Open-LLM-VTuber 빠른 시작: Windows에서 로컬 LLM(Ollama)로 실행하기

나만의 젊탱버 만드는법 따라하기
Open-LLM-Vtuber 프로젝트를 설치하고 구동하는 것 까지
Open-LLM-Vtuber란?
오픈소스로 만든 음성 기반 상호작용 AI 캐릭터 플랫폼
Live2D 아바타와 함께 실시간 음성 대화 및 표정 애니메이션을 구현함
- 대화 엔진 : OpenAI를 포함하여 여러 LLM 백엔드를 지원. 로컬 모델도 사용 가능. 원하는 LLM을 선택해서 상호작용이 가능함
- 음성 처리 : ASR(음성 -> 텍스트) 및 TTS(텍스트 -> 음성), 음성 인식 가능
- Live2D 아바타 : 캐릭터 표정 및 입 모양 도기화 지원
- 시각적 인식(카메라, 화면 녹화 및 스크린샷), MCP 지원, 브라우저 제어, 라이브 스트리밍 연동 등
- 오프라인 실행 가능, 크로스 플랫폼, 대화 기록 유지 일부 가능
배포 구성은 Ollama + sherpa-onnx-asr(SenseVoiceSmall) + edge_tts로 이루어짐
모든 작업은 크롬 사용을 권장함
- 권장사양
- OS : MAC(M 시리즈 칩), Window, Linux
- HW : NVIDIA GPU 또는 AMD GPU(ROCm) , 혹은 GPU 성능을 대체할 수 있는 CPU
- 음성 인식(ASR), 대규모 언어 모델(LLM), 텍스트 음성 변환(TTS)을 위한 다양한 백엔드를 구동해야하므로,
하드웨어 사양에 맞춰서 선택해야함. 반응 속도가 너무 느리다면 더 작은 모델을 선택할 것
환경 세팅
윈도우, Nvidia 그래픽 카드 기준으로 설명
1. Git 설치
Windows 패키지 매니저(winget)로 Git for Windows를 설치한다
1
winget install Git.Git
만약 Window 버전이 구버전이라 Winget이 없다면 Microsoft Store에서 Winget을 설치할 것
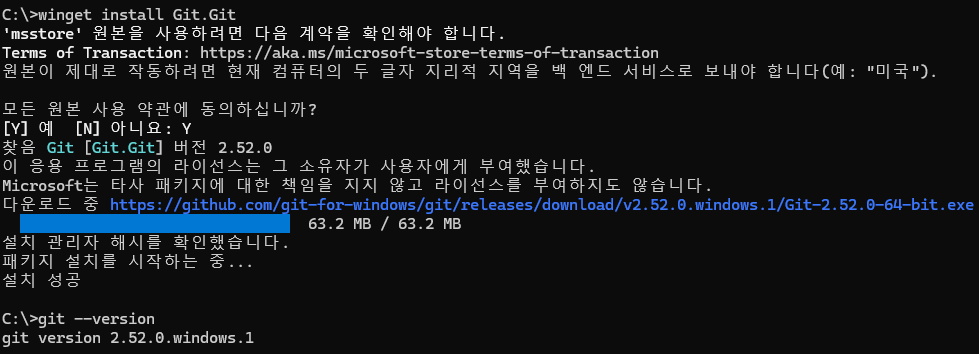
설치 완료 뜨는거 확인하고 git --version으로 설치 제대로 되었는지 체크
2. FFmpeg 설치
미디어 포멧 변환 도구인 FFmpeg 설치
1
winget install ffmpeg
마찬가지로 설치 후 ffmpeg -version으로 설치 체크
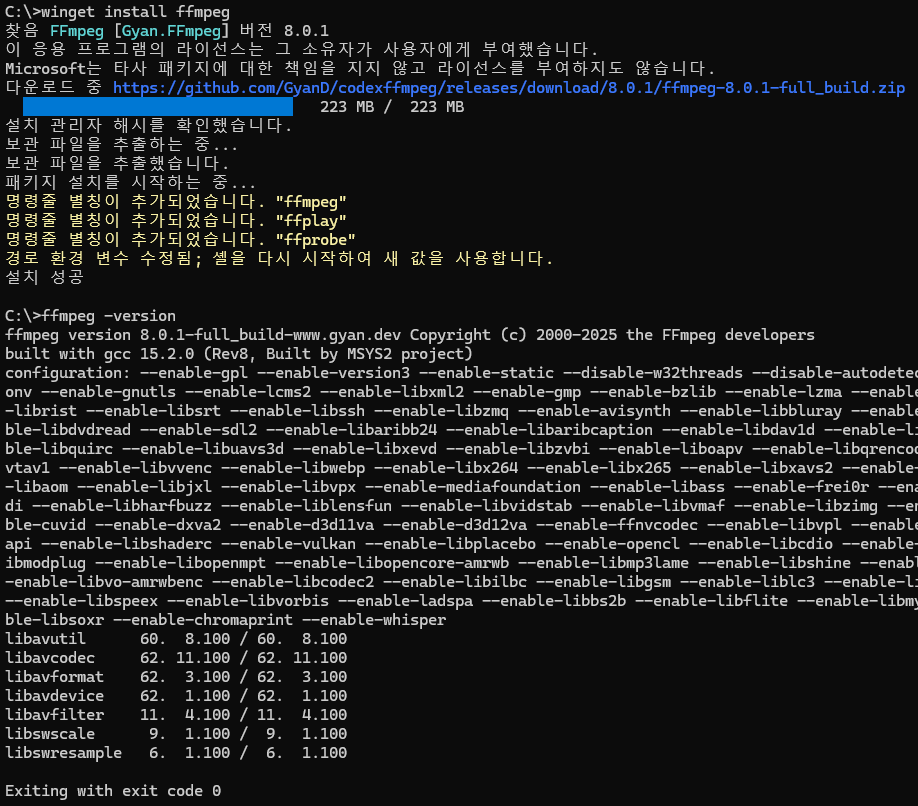
버전은 상관 없는듯
3. NVIDIA GPU Supprot
3-1. NVIDIA GPU 드라이버 설치
Nvidia Experience 혹은 공식 페이지에서 드라이버를 최신 드라이버로 업데이트3-2. CUDA ToolKit 설치(버전 11.8 or 이상)
먼저 CUDA 버전 호환성 페이지에서 드라이버 버전에서 지원하는 CUDA 버전을 체크한다
2.2 CUDA Driver항목을 보면, 각 GPU에 호환되는 CUDA Toolkit이 설명되어있다.
RTX3080에 591.44 버전을 사용중이므로CUDA 13.1을 사용했음
이후 해당 버전에 맞는 CUDA Toolkit을 CUDA Toolkit 다운로드 페이지에서 다운로드 한다
자신의 환경에 맞는 설치 타입을 선택 후 설치 진행
이후 환경변수를 추가한다

자신이 설치한 Toolkit의 경로로 들어가서
bin과lib\x64경로를 환경변수 > 시스템 변수에 추가해준다
1
2
3
# 경로와 버전이 자신의 환경과 맞는지 꼭 확인할 것
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v13.1\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v13.1\lib\x64\
3-3. 일치하는 버전의 cuDNN 설치
cuDNN 다운로드 페이지에서 설치한 CUDA 버전에 맞는 cuDNN을 설치한다
꼭 자신의 Toolkit에 맞는 cuDNN을 받아야 문제가 발생하지 않는다 주의할 것!!!!
cuDNN Supprot Matrix에 어떤걸 받아야 하는지 나와있으므로 확인 가능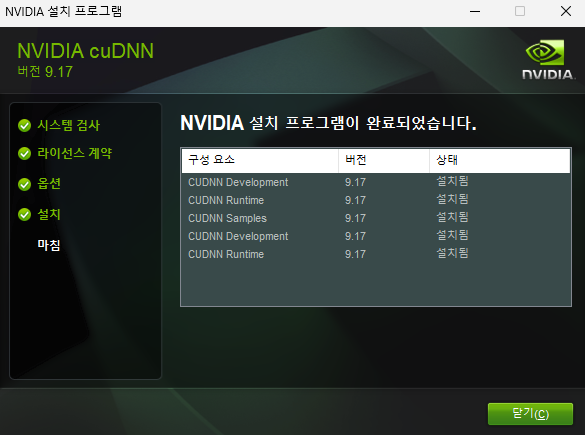
13.1을 받았으므로,
cuDNN 9.17.0을 받아서 설치
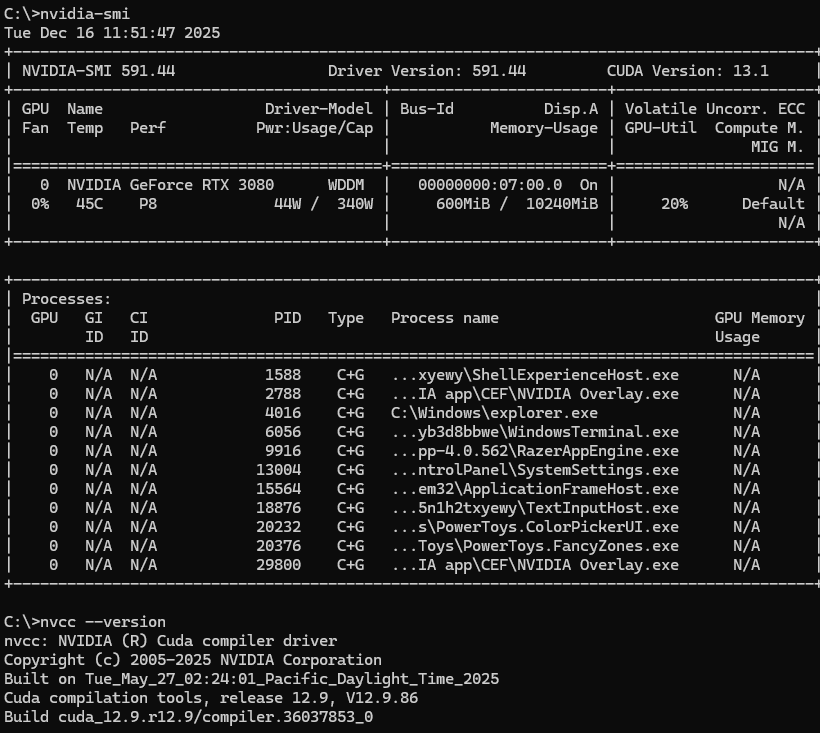
설치가 다 됬다면 nvidia-smi, nvcc --version으로 설치 확인
4. 파이썬 환경
open-llm-vtuber 버전 1.0.0 부터 uv를 종속성 관리 도구로 사용할 것을 권장하고 있음
uv는 파이썬 전용 패키지 및 가상 환경 관리 도구로,
conda와 유사하지만, 더 빠르고 패키지에 특화되어있음
1
winget install --id=astral-sh.uv -e
uv를 설치한다

여기까지 왔다면 환경 세팅은 끝
배포
1. 프로젝트 코드 다운로드
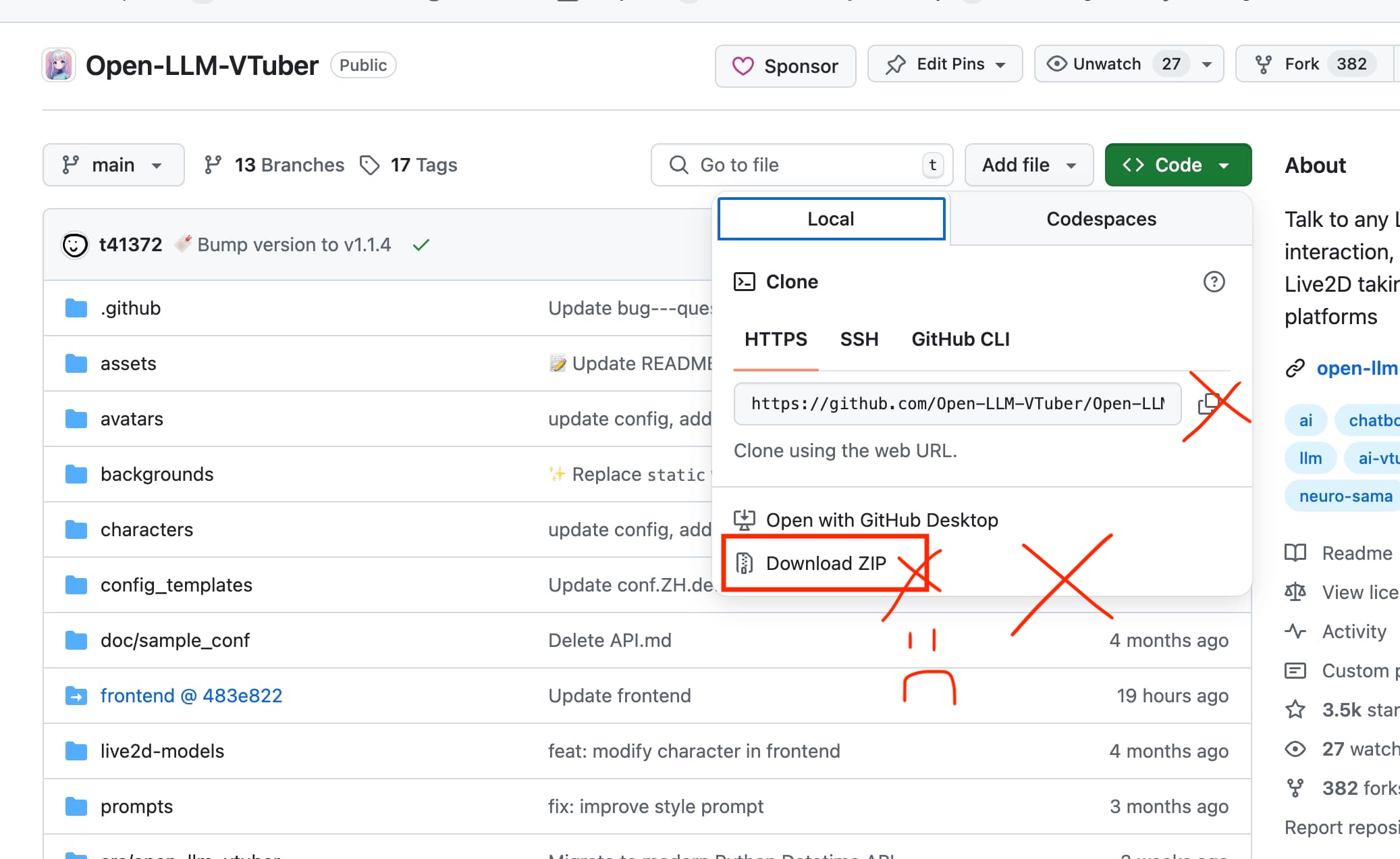
절대로 코드 버튼을 통해 깃허브 주소를 통해 받아오거나, 코드를 ZIP 파일로 받지 말라고 한다
Git 정보가 포함되어있지 않기 때문에 문제가 발생할 수 있다고 함
릴리즈 페이지에서 직접 ZIP 파일을 받거나 아래 명령어를 통해 받을 것
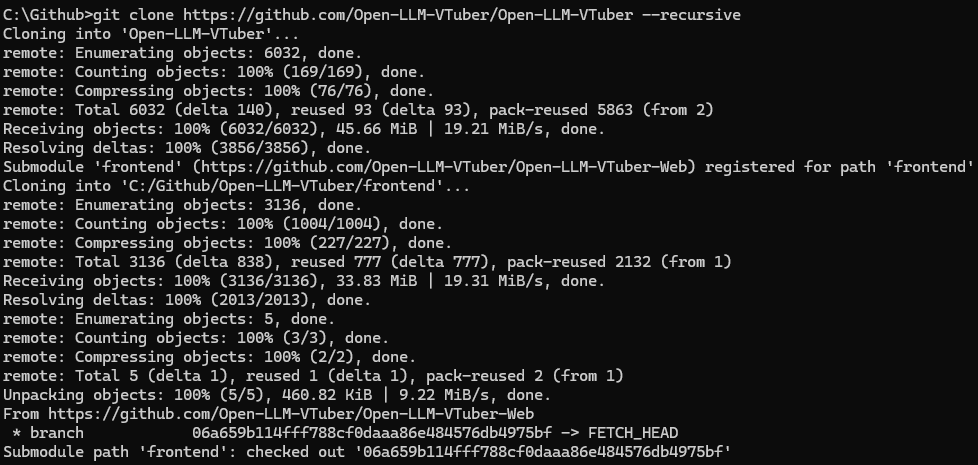
git clone https://github.com/Open-LLM-VTuber/Open-LLM-VTuber --recursive
별도로 웹이 아닌 데스크탑 클라이언트나 PIP 모드로 사용하고자 한다면,
위의 릴리즈 페이지에서 open-llm-vtuber-x.x.x-setup.exe 실행파일을 받으면 된다
2. 프로젝트
uv --version으로 uv가 제대로 설치되었는지 체크
이후 해당 레포의 루트 경로로 이동하여 uv sync로 필요한 구성요소들을 설치한다
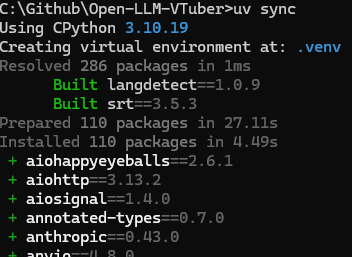
정상적으로 설치 된 것을 확인 후 아래 명령어를 실행
1
uv run run_server.py

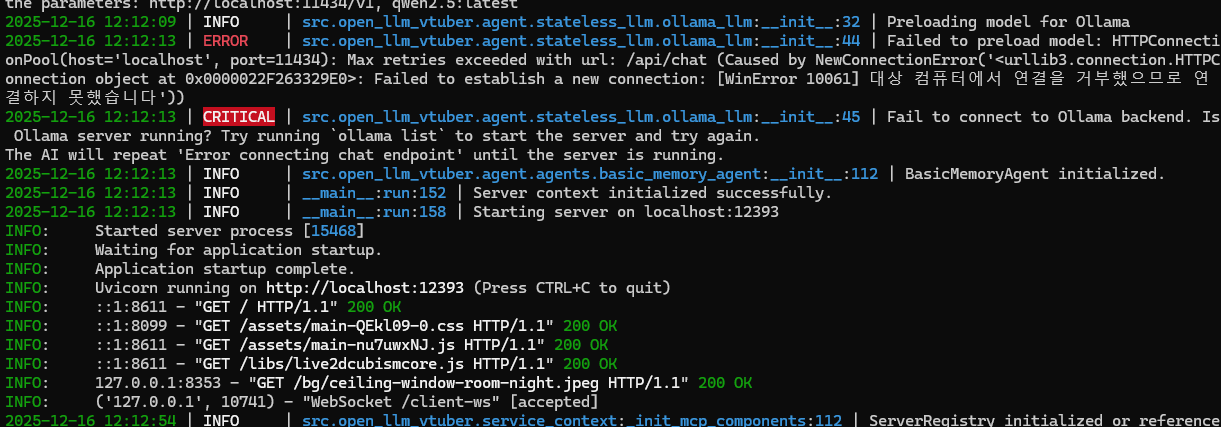
서버를 한번 구동시켜서 필요한 설정 파일을 생성하도록 한다
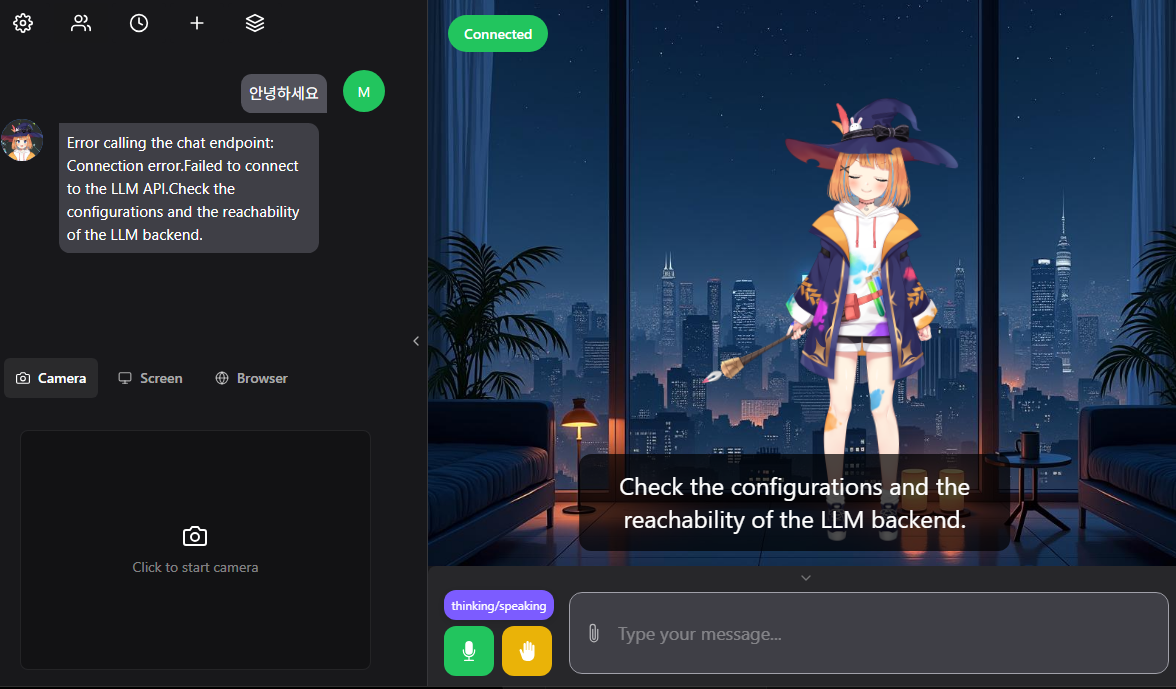
좀 오래 기다리면 자동으로 프론트엔드로 연결되는데, 입력해도 에러를 밷는다
현재 연결된 백엔드 LLM이 없기 때문에 뇌가 없는 상태임
ctrl + C로 서버를 종료해준다
3. LLM 설정
자신이 사용하고자 하는 LLM을 연결한다
로컬 LLM은 Ollama를 사용하고, 그 외는 API를 통해 연결한다
OpenAI, Gemini, claude 등 다양한 API를 지원함
LLM Configuration페이지 참조하여 연결할 것
주의 : 모델을 선택할 때, VRAM과 GPU 연산 능력을 고려해서 선택해야한다.
모델 파일의 크기가 VRAM 용량보다 크면 CPU 연산을 사용하게 되어 속도가 매우 느려진다
또한 파라미터가 클수록 대화 지연시간이 커지므로, 알맞게 선택할 것
퀵 가이드에서는 로컬 LLM을 사용했는데, 쉽게 그냥 OpenAI 연동하는걸 추천함
일단은 메뉴얼대로 Ollama를 사용하여 로컬 LLM으로 시도해봄
- Ollama를 이용한 로컬 LLM 연결
3-1. Ollama 설치
먼저 로컬 LLM용 Ollama를 설치한다. 자세한 설치는 Ollama 메뉴얼 참조

이후 설치가 제대로 되었는지
ollama --version으로 체크한다3-2.
qwen2.5:latest예시 모델 설치qwen2가 뭔가 찾아보니, 알리바바의 LLM 모델이라고 함
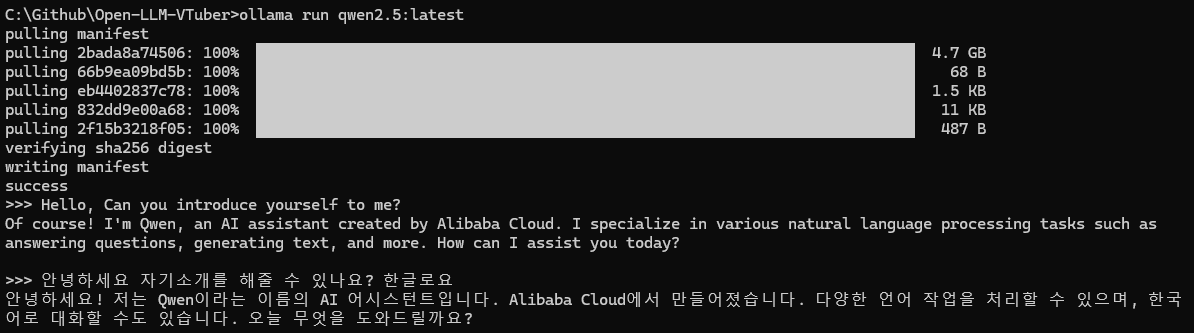
설치 후 CLI 환경에서 동작하는지 체크
별도의 로컬 LLM이있다면 여기서 활성화 해주면 된다
이후
ctrl + D로 셀을 종료.
ollama list로 설치된 LLM을 체크한다3-3
conf.yaml파일을 수정한다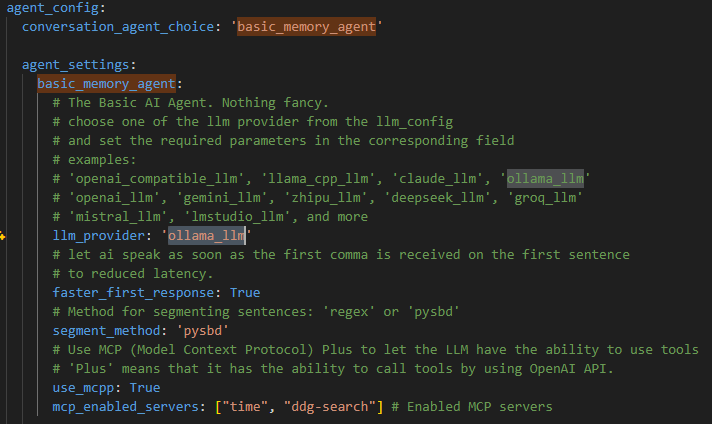
conf.yaml파일 내의basic_memory_agent의llm_provider를ollama_llm으로 설정
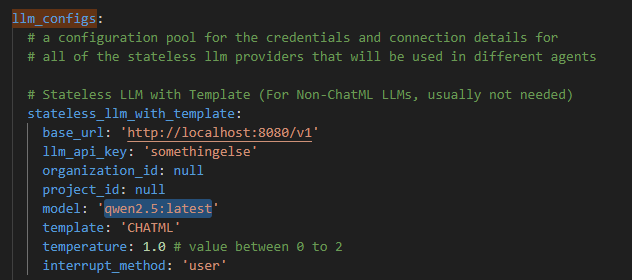
llm_configs설정 내의base_url,model이 설정되어있는지 체크한다. base_url은 접속 포인트, model 은 자신이 사용할 로컬 LLM의 이름(ollama에서 사용하는)으로 설정한다.temperature는 응답의 랜덤성 파라미터임. 0~2 사이에 값을 넣어서 높을수록 엉뚱한 대답을 함
실행
1
uv run run_server.py
위 명령어를 입력하여 백엔드 서비스를 실행한 뒤, 위의 Base url로 접속한다.
실행하면 이전과 다르게 왼쪽 위에 LLM와 connected 가 정상적으로 된 것을 확인할 수 있다
자기소개 부탁드려요
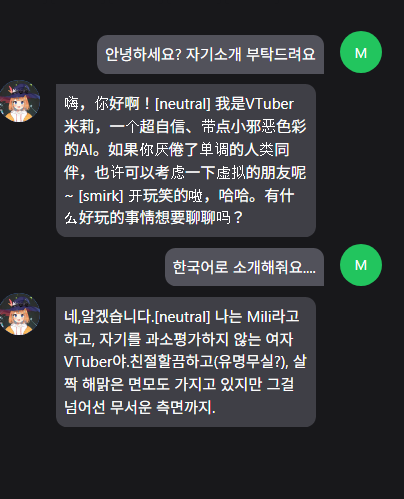
그냥 OpenAI 무료 토큰 쓸게요…
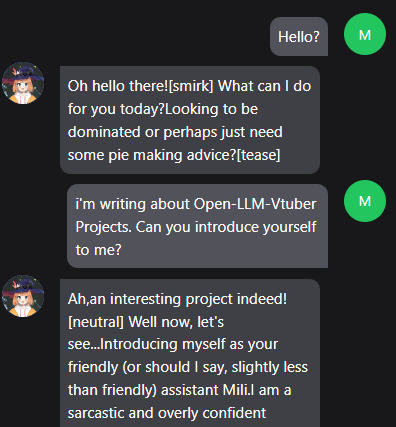
영어로 물어보니 차라리 좀 낫다
다음 글에선 캐릭터 성격 및 판때기 바꾸는 법을 알아보도록 하겠다