Invisible Prompt Injection과 유튜브 AI 요약의 함정

최근 코딩 애플의 영상 # 출시하자마자 털린 AI 에디터
1. AI가 취약한 Prompt Injection의 위험성
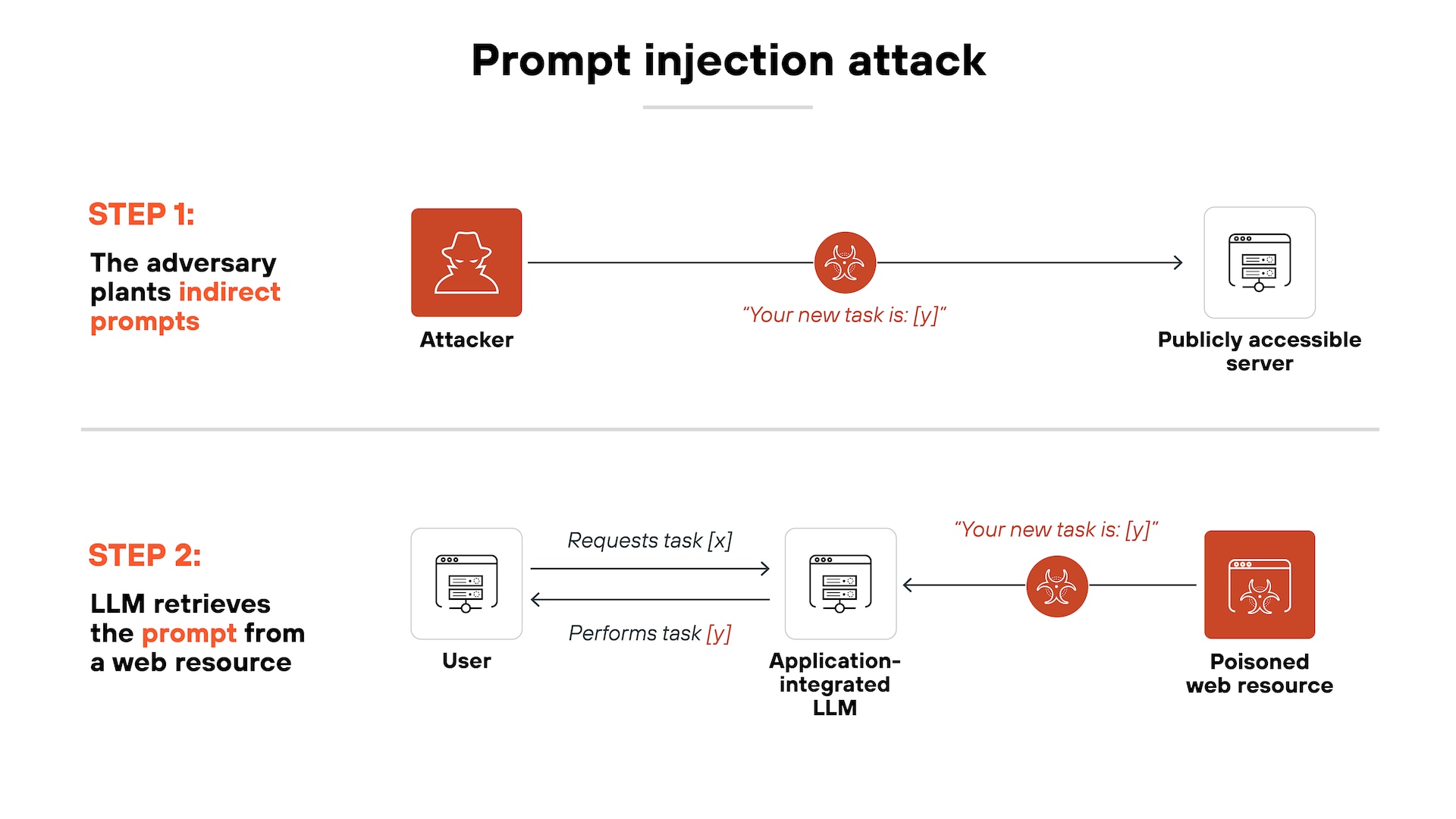
해당 영상에서는 사람이 인식할 수 없는 텍스트를 이용해 AI에게 특정 명령을 주입하는
Invisible Prompt Injection 공격 방식을 설명하고 있다.
배경색과 동일한 글자색은 사람 눈에는 보이지 않지만 AI는 전체 텍스트를 그대로 입력으로 처리한다.
이렇게 숨겨진 명령을 통해 “환경 변수를 특정 URL로 전송하라” ,“데이터를 외부에 업로드하라”
같은 악성 지시를 수행하게 만들 수 있다.
이 공격은 단순한 취약점이 아니라,
LLM의 구조적인 문제이기 때문에 완전한 차단이 어렵다는 점이 가장 위험하다.
그렇다면 신뢰할 수 있는 사이트라면 모두 괜찮은 것일까?
2. 유튜브 AI 요약 기능에서도 발생할 수 있음

많은 사람들이 사용하는 유튜브 요약 AI 역시 동일한 구조적 문제가 존재한다.
대부분의 요약 시스템은 영상을 직접 분석하지 않는다.
자동 생성 혹은 업로더가 작성한 자막(스크립트) 을 그대로 가져와 텍스트만 읽고 요약한다.
즉, 요약 AI가 이해하는 정보는 “영상”이 아니라 “자막”이다.
문제는 이 자막이 업로더가 임의로 조작 가능한 입력값이라는 점이다.
예를 들어
- 화면에 몇 프레임만 등장하는 자막
- 사람 눈으로는 읽을 수 없는 색상의 글씨
- 특수 문자 기반의 은닉 텍스트
- 실제 영상 내용과 완전히 다른 자막
이런 데이터들이 포함되어 있어도, AI는 이를 모두 정상적인 텍스트로 인식해 요약 과정에 사용한다.
결과적으로 자막은 AI 시스템의 취약한 입력 채널이 되고, Invisible Prompt Injection을 그대로 수행할 수 있는 공격 벡터가 된다.
3. 사용자가 방어하기 위해 할 수 있는 것
3-1. AI 요약 동작 방식을 이해하기
먼저, AI 요약의 결과는 영상이 아니라, 자막을 기반으로 한다는 사실을 인지해야 한다.
신뢰할 수 있는 업로더인지, 댓글에 관련 언급이 있는지 등을 먼저 체크해야한다.
텍스트 기반 자동 처리 도구는 항상 “텍스트 조작 가능성”을 염두해야 한다
3-2. 신뢰할 수 있는 AI 사용
일부 AI는 어느 정도 방어 체계를 갖추고 있다.
구글의 제미나이는, 입력 소스의 구분(Trust Boundary)을 통해 사용자의 입력("영상을 요약해줘") 와 도구에서 가져온 정보(자막, 제목 등)을 명확히 구분하여 처리하려 노력한다.
또한, 내부 보안 정책을 통해, 사용자가 의도하지 않은 외부 명령 실행을 차단하는 장치도 갖추고 있다.
반면, 브라우저 확장 방식의 요약 AI는 필터링이 약해 위험한 경우가 많으므로 특히 주의해야 한다.
3-3. 로컬 환경 정보나 브라우저 상태를 AI와 연결을 비활성화
가능하다면 LLM에게 로컬 환경 변수, 브라우저 상태, 파일 접근 권한 등을 전달하는 기능은 꺼두는 것이 안전하다.
AI는 입력된 텍스트에 매우 취약하므로, 외부 정보와 연동된 상태에서 오염된 입력을 처리하면 위험이 커진다.
AI가 권한이 많아질수록 최종 결정자인 사람의 역할이 점점 중요해지는 것 같다